If you’re an MSP and you need to keep track of your customers Microsoft Windows 10 versions, you might have already turned to Power BI to make sense of all that data exported from your RMM system.
Power BI is great for this, but how do you keep track of all the different Windows 10 builds there are out there and their various support expiry dates for Pro and Enterprise versions?
It used to be easy enough to web scrape some tables from the Microsoft website, but no longer. To navigate this challenge I’ve ended up publishing a list I’ve called the WinVerProject which uses Power automate, Azure SQL and GitHub (because it’s free!) to automatically build and publish a list that you can use in your own Power BI reports.
The WinVerProject is hosted in GitHub. If you click on the link you can read the README.md file which explains what I won’t repeat here. This article describes how it works.
Most of this is covered in a previous article so I’ll gloss over a fair bit of it.
I have a very simple table in Azure SQL
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[WindowsVersions](
[WindowsVersions] [nvarchar](max) NULL
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
Next, in Power Automate I have a flow with a scheduled trigger. This can run every 3 months or every month or whatever; there are only two releases a year.
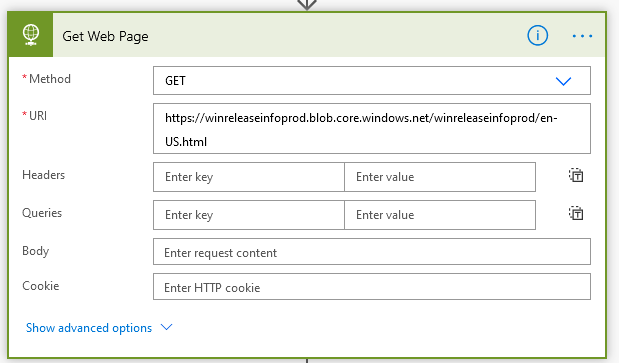
Get the web page with the version table in it:
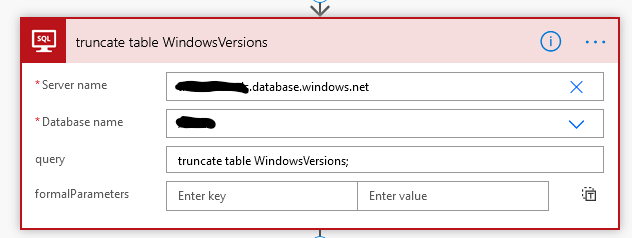
Truncate the Azure SQL table created earlier:
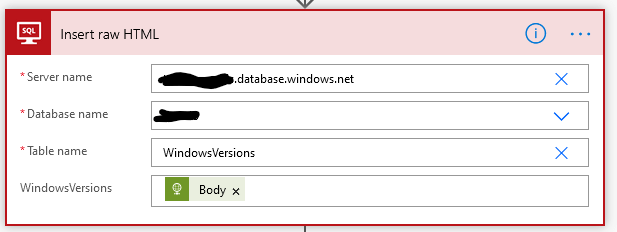
Put the response into that table:
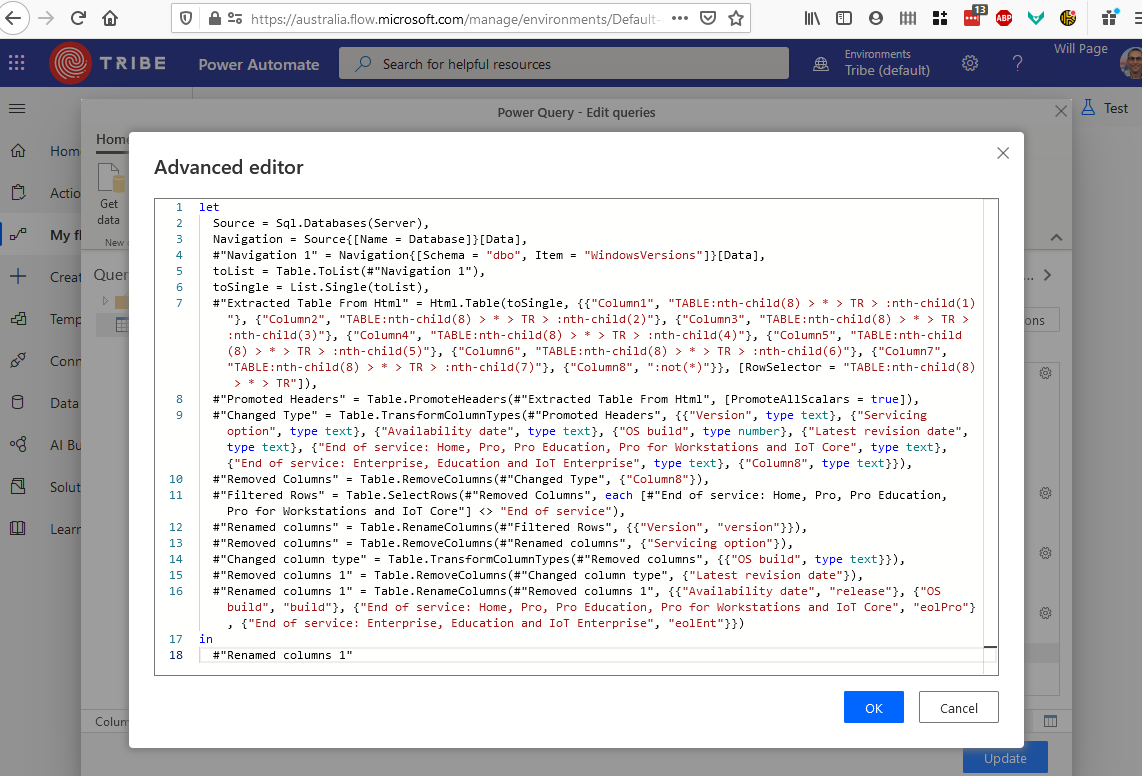
Do some transformation in Power Query using the “Transform Data using Power Query” action (this feature is awesome, by the way):
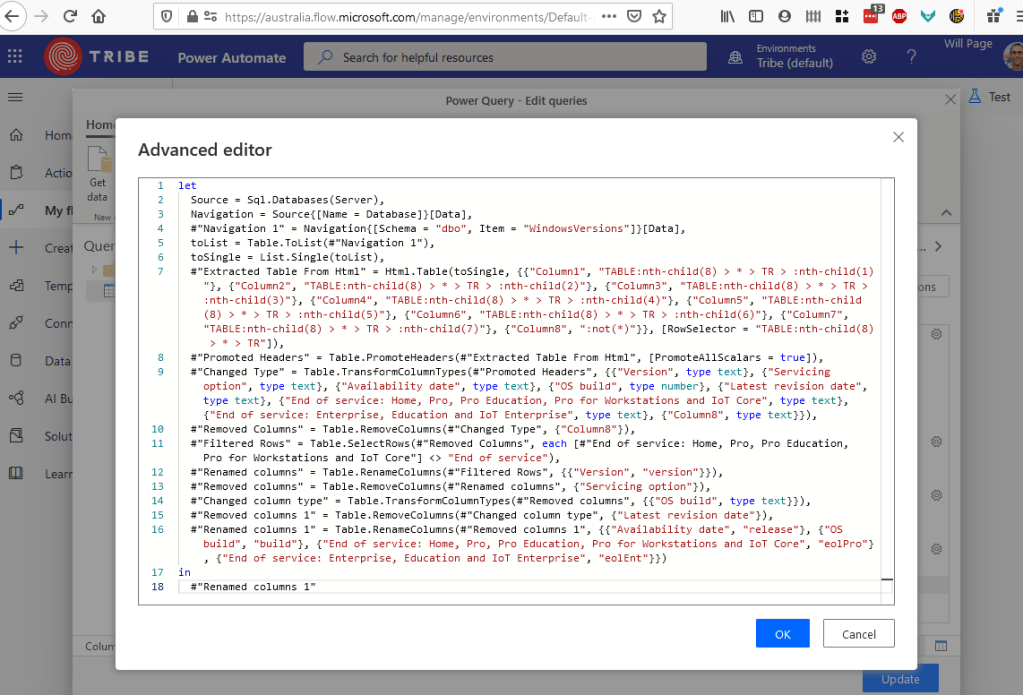
Here’s the result. The action outputs a JSON array:
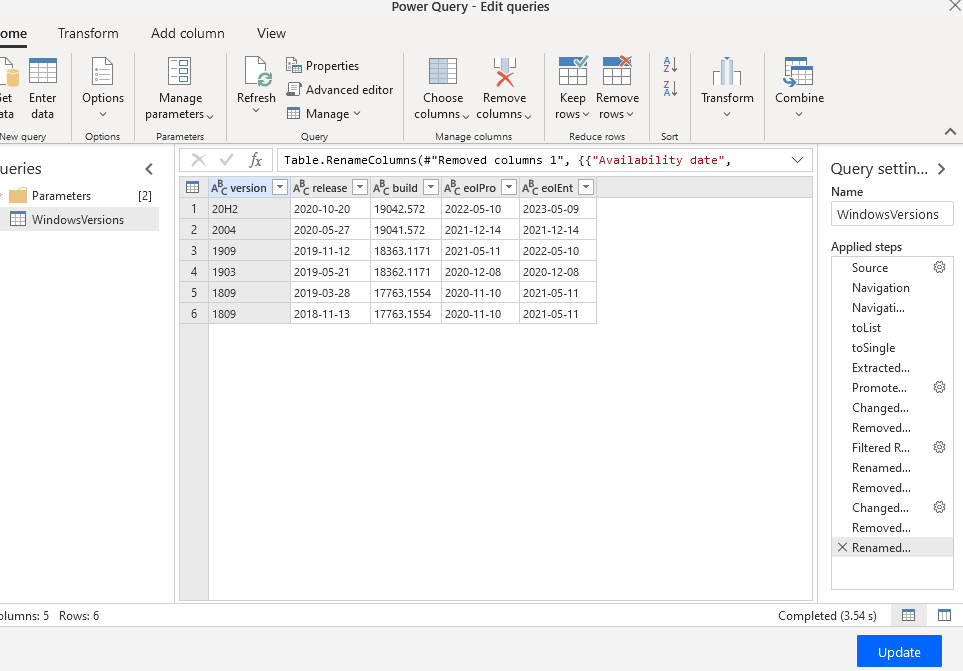
You might notice that table above only goes back to 1809, which is sort of the whole reason I did this. In the GitHub repository I have a JSON file called win10versions.json which started out being manually typed with older Windows 10 versions, build numbers and key dates that I partly grovelled around the web for and partly had in PBI reports I made before Microsoft pulled the complete table. I’m missing the Enterprise SKU expiry dates for the earliest versions so if anyone has that I can update the file.
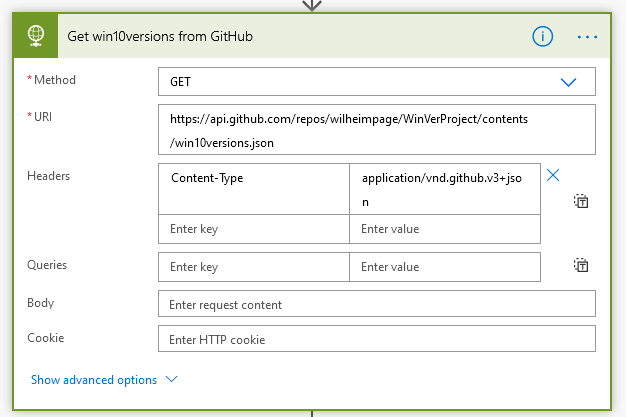
Anyway, GET that. I’ve used the GitHub API here because I need the sha hash of the file blob which the GitHub API needs to update the file contents later, and they conveniently provide this in the response instead of having to calculate it yourself.
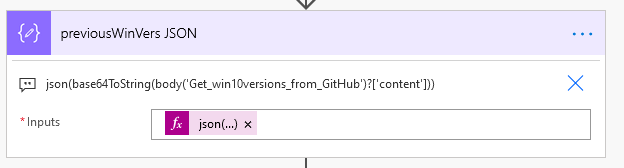
The GitHub API returns the file content in base64 so I decode that, then deserialise it with the json() function.
Now I create a one-dimensional array of the Windows version numbers from the Power Query output using the Select action:
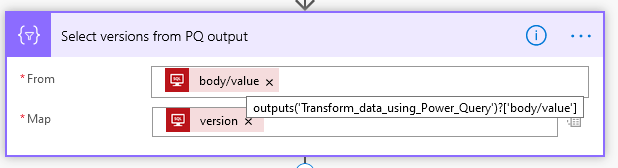
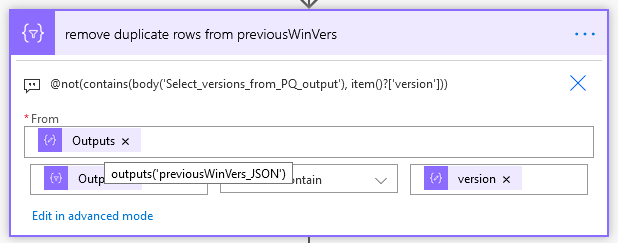
Now I want to filter out any rows from the GitHub file that exist in the power query output:
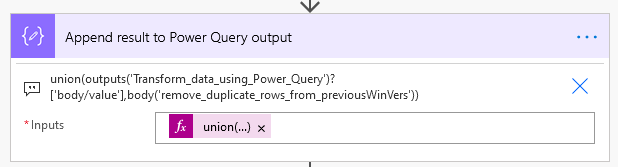
Now append the result to the Power Query output using the union() function:
Now the last thing is to push the resulting array back to GitHub.
To update an existing file in GitHub using the API you first have to do a GET, then use the sha attribute in the PUT. We already retrieved the file content from GitHub to use as a basis for the new table, so that data is already available to use in the next request body.
The result of that union() function is the content to update the file:
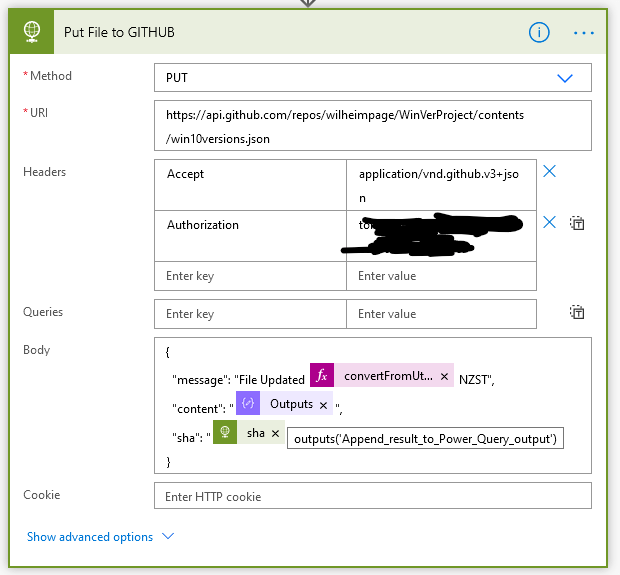
GitHub is smart enough to know whether or not the file content has actually changed, so the file as it’s displayed in the repo will have a last modified and message consistent with the last time there was an actual change to the content, not necessarily the last time the flow ran.
That’s it. The data is publicly accessible and if you have a use for it then you can work it into your Power BI reports. I’d suggest using a flow or logic app to get the data from GitHub and sinking it into your own data source, like a SharePoint list, so you can incorporate it into your published PBI reports without using the on premises data gateway, which you need for the Web.Contents() function in Power Query.
