
By default, there’s not much in a flow or logic app to notify you of a failure. Power Automate will send you an email when one or more of your flows have failed, some hours after the fact, and it’s up to you to figure out what happened by opening the failed flow run and having a look.
Microsoft publish a pretty good article here that has a lot of the below in it. It’s quite Logic Apps focussed though, and there are many ways to achieve an end result. Mine varies a bit from Microsoft’s guidance.
Thankfully both platforms include features that allow you to create quite slick error catching. These include:
- Retry policy on actions
- Timeout on actions
- Run-after
- Branching conditions
- Scopes
- The result() function
The first two are at the action level – that is to say they are properties of individual actions that you can access by clicking the ellipses and going into Settings:
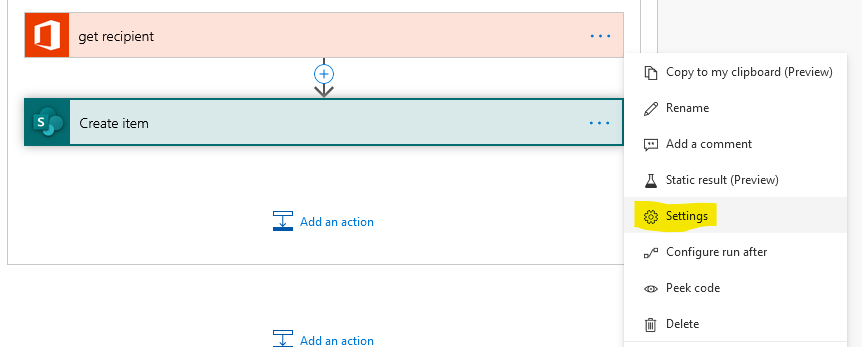

Retry
Retry policy is useful when you’re making a lot of API calls and they sometimes fail due to being rate limited/throttled. Writing a lot of rows into a SQL database in an Apply to each loop for example, when you set the concurrency of the loop right up to 50.
This kind of error can be handled at the action level if you’re experiencing it, by adjusting the retry policy such that your flow never fails. Your mileage may vary on this depending on the action and the behaviour of your flow.
If you have persistent throttling issues I suggest looking through this article which has some detailed workarounds for throttling issues, but in my experience you can usually solve it with a simple exponential retry.
Timeout & Branching
Timeout policy is particularly useful for Approvals and other actions that wait for a response like some of the Teams adaptive cards actions. If you wait for a response in a flow and the user never responds it’ll wait for 90 days or whatever it is and then the whole flow will fail.
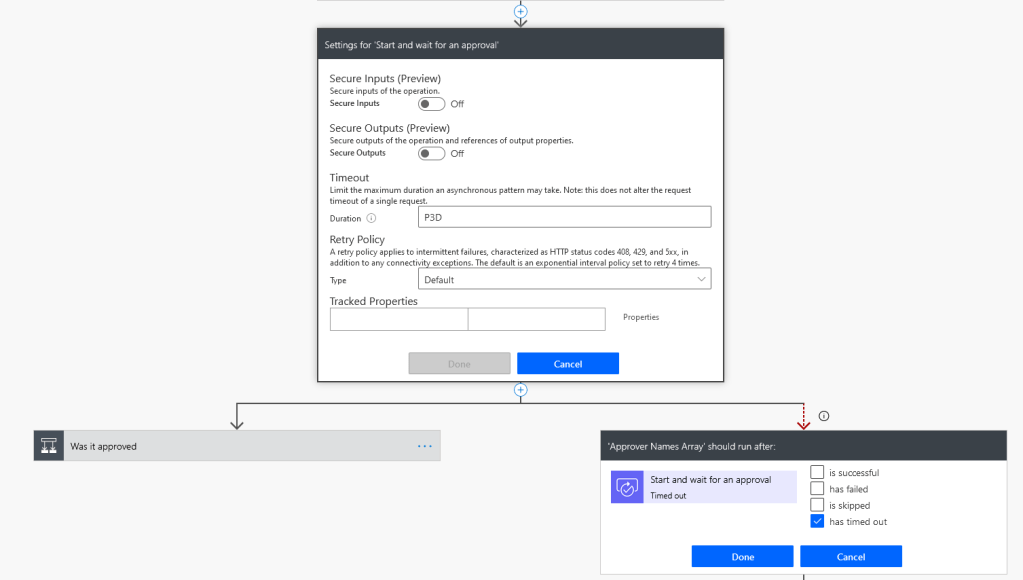
You can use the timeout duration e.g P1D for one day, PT3H for 3 hours etc. to only allow the action to wait for a fixed time period. Then a branching condition underneath where one branch goes down the route of a successful response from the user and the other branch has a Run-after status of “timed out” and takes actions when the user has failed to respond, such as an implicit approval or escalation to another approver.
In this screen shot you can see the settings for “Start and wait for an approval” has a timeout duration of 3 days, and a branching condition underneath that runs when it has timed out – a catch:
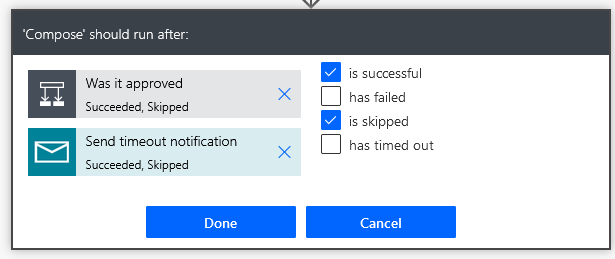
You can fan back in at the bottom of branching conditions by adding an action in the centre + New step button, but if you do, you must set its run after property for both previous actions to “is successful” and “is skipped” because the central action by default, will only run if both branches return a successful result. This will obviously never happen if they never run together. This would be the equivalent of your “finally” block in traditional programming:
Scopes
Scopes are great for error handling. A scope is a collection of actions. The presence of a scope doesn’t change the way a flow runs, but it does make it easier to read, and the output status of a scope reflects the output status of the last executed action within it.
For example, you create a scope with 5 actions inside. They all execute successfully then the status of the Scope is successful and subsequent actions can run-after normally. If any of the 5 actions inside were to fail then the output of the scope is failed, and any subsequent actions run-after can either execute or not, based on that, regardless of which individual action inside failed.
This means you bunch related action inside a scope and handle errors within them, and if you structure your flow intelligently, actions elsewhere in the flow that don’t depend on the scope succeeding can run anyway.
For example, you might have a flow that copies email attachments to a SharePoint library, sets the values of some columns, notifies somebody and deletes the original email from the mailbox. You might want the email to be deleted even if the notification fails. You can do that with scopes and run-after.
Using scopes, branching conditions and the run-after settings, you can try, catch and throw errors in any stage of your flow.
The result() function
There’s a great function in Power Automate and Logic Apps; result(). I learned about this in John Liu’s blog here so kudos to him because there’s no way I’d ever have learned about it otherwise. At the time it was undocumented, but it’s since found its way into the official function reference here.
The result() function can be used to get the outputs of all the actions inside any group of actions. Those are Apply to each/For each, Until/Do until and Scope.
The output of result(‘Scope’) is an array, with one element of the array for each action inside the scope. The data contains the name, inputs and outputs of the actions, which includes the status, and the client tracking ID (the workflow ID) etc.
Putting it together
Here is a flow for capturing praise in Teams. I’ve blogged about this here. There is no error handling in this flow, but it is divided into 3 main sections by using scopes:
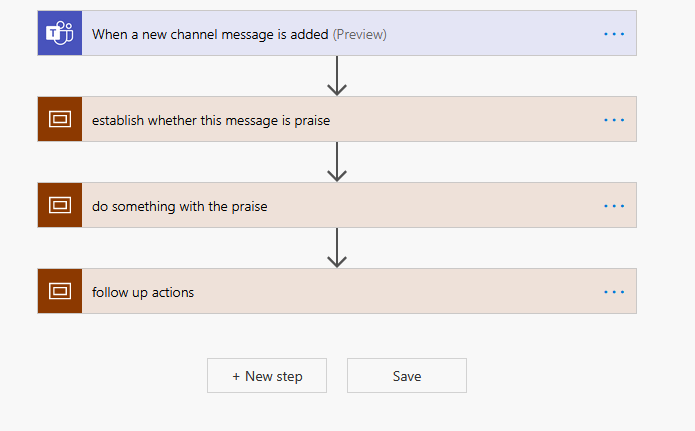
For each of these scopes, I’ll add a scope to catch and throw any errors.
Add a parallel branch:
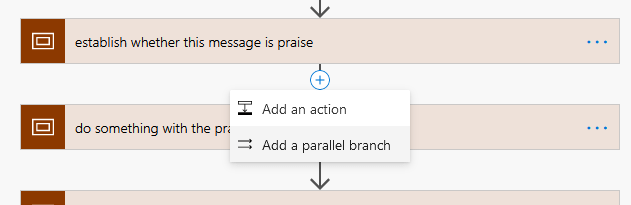
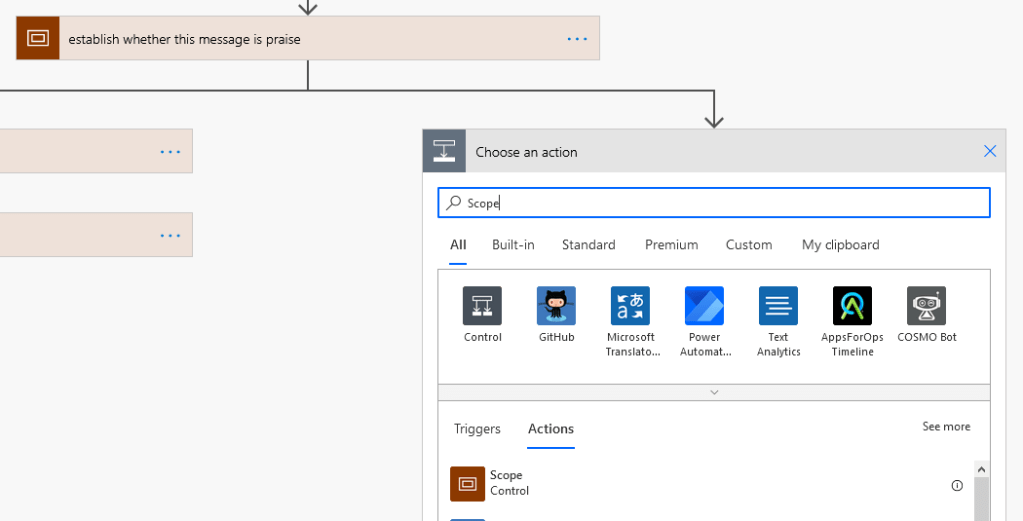
Choose Scope:
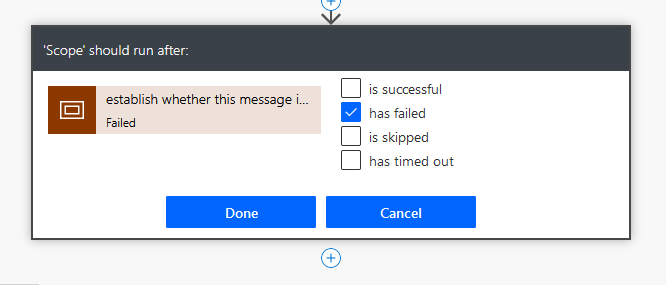
Configure run after: Failed.
Now I rename it to exactly the same name as the parent scope but with the word failed at the end. This is more of a Logic Apps thing: If you have a lot of scopes, you can build up one error handling scope, and as long as the scope name and the names of all the actions within it contain the parent scope name exactly, you can copy the code into a text editor, do find and replace of the scope name with the next one (substituting spaces with underscores) and paste it back it and it’ll automagically appear in the right place with the correct run-after etc. This is Power Automate so it’s no so important but I do it anyway.
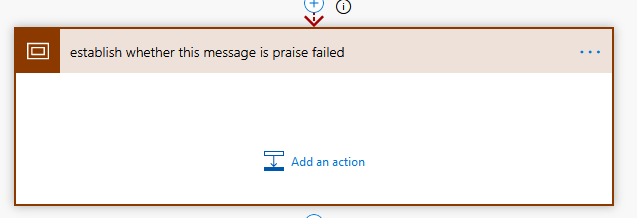
Inside I want to use that result() function. Create a Compose for this:

The result() function outputs a JSON array that contains the status, inputs and outputs of all the actions within the scope it references. It can be rather large if your scope contains actions that get large amounts of data.
Next we want to filter this array for the action that failed. Add a Filter array action:
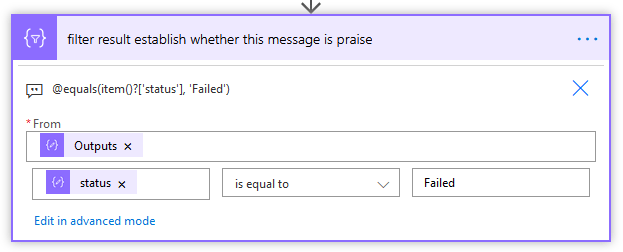
We know there will be an output to this filter condition because we don’t go down this branch unless the previous scope failed. This filters out any successful actions within the scope that executed prior to the failure, so if you did happen to get 5000 rows from a table, we get rid of those. Not only is this good for the readability of the error message, you eliminate data leakage issues.
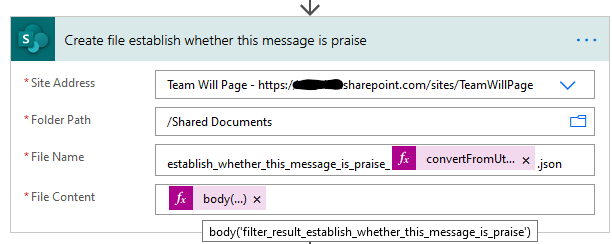
Now create a file in SharePoint. Note the scope name in the file name. I also add a timestamp to avoid file naming conflicts. The content is the output of the filter array:
Create a sharing link:
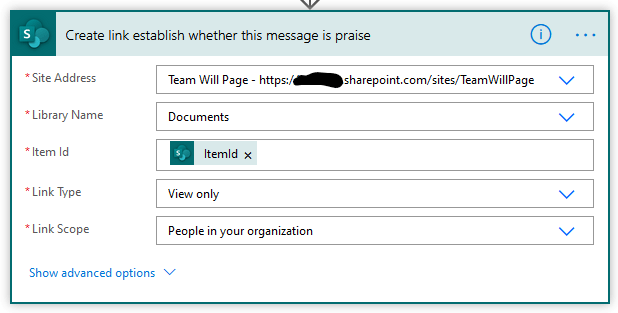
For some reason I can’t explain, a direct link to JSON files gives you a 404 in SharePoint, so this is a workaround.
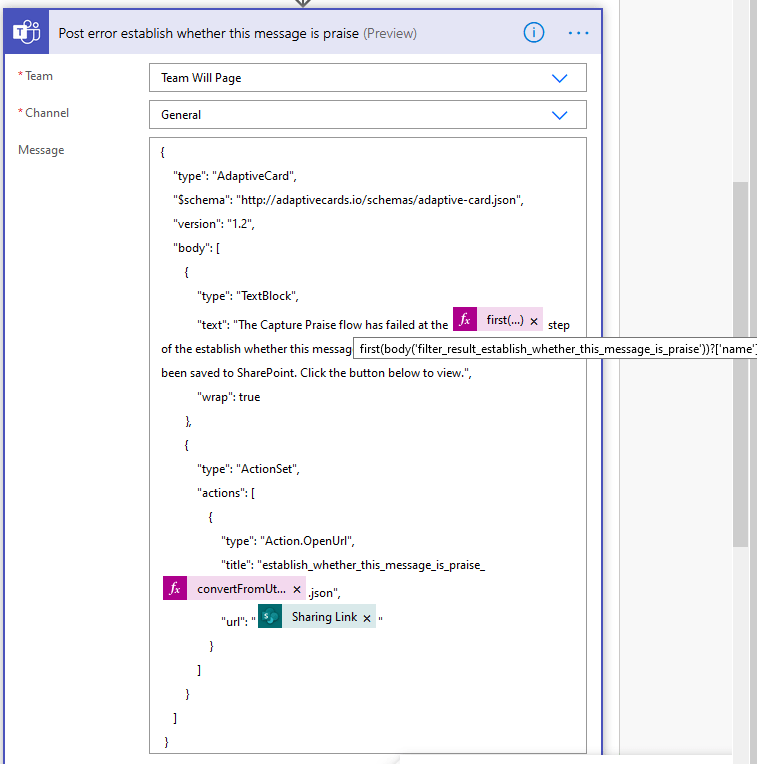
Next up, post an error message to a Teams channel. This way your whole team can see it and you can discuss who is going to action it. I much prefer this to email. This adaptive card contains a link to the error message from the failed action, and some detail: The name of the flow that failed, the scope that failed, and via the highlighted expression, the name of the actual action that failed. You could also include the error message here too, but they’re often quite verbose so I prefer to leave it to the person to open the file to see that.
That’s pretty much it.
There’s nothing particularly exciting about error handling, and personally I find it quite tedious when I’m working on some exciting project, to have to put on the brakes and make sure there’s solid error handling built in.
It’s worth it in the long run though, because even the best developers can’t think of everything that might happen and build it into the flow on day 1.
